前端题目思考总结
前端工程化
- 代码规范化
- 单元测试
- 自动化测试
- webpack 打包
- 自动化部署
- 监控系统,埋点
- Sentry:异常上报系统
监控系统,异常上报系统
- 监控原理,获取 js 错误和网络异常
onerror捕获前端错误
window.onerror = (msg, url, line, col, error) => {
console.log('onerror')
}
- promise
onerror事件无法捕获到网络异常的错误(资源加载失败、图片显示异常等),例如img标签下图片 url 404 网络请求异常。此时需要监听unhandledrejection
当Promise 被 reject 且没有 reject 处理器的时候,会触发 unhandledrejection 事件
window.addEventListener('unhandledrejection', function (err) {
console.log(err)
})
- 错误信息上报
JS 和 TS 的区别
- TS 多出来的类型:tuple、enum、any
- TS 是 JS 的超集,可以被编译为 JS 代码,完全兼容 JavaScript
- JS 是基于对象的,一种脚本语言。TS 基于面向对象编程,引入了很多面相对象程序设计的特征
(所以对于熟悉C#、Java和所有强类型语言的开发者来说,TS 容易上手),包括
- interface 接口
- classes 类
- enumerated types 枚举类型
- generics 泛型
- modules 模块
- TS 支持可选参数,JS 则不支持该特性
- TS 支持静态类型,JS 不支持
- TS 支持接口,JS 不支持
- TS 在开发时编译可以知道错误,JS 错误则需要在运行时才能暴露
- TS 作为强类型语言,可以明确知道数据类型,代码可读性强。
| JS | TS |
|---|---|
| JS 不支持强制类型或静态类型 | TS 支持强制类型或静态类型 |
| 只是一种脚本语言 | 支持面相对象的编程概念,如类、接口、继承、泛型 |
| 没有可选参数特性 | 有可选参数特性 |
| 是解释语言,在运行的时候才会暴露错误 | 编译代码并在开发期间暴露错误 |
| 不支持泛型 | 支持泛型 |
| 不支持 ES6 | 支持 ES6 |
| 不支持模块 | 支持模块?? |
| number 和 string 是对象 | number 和 string 是接口?? |
泛型(泛指某类型)
泛型 : 在像C#和Java这样的语言中,可以使用泛型来创建可重用的组件,一个组件可以支持多种类型的数据。 这样用户就可以以自己的数据类型来使用组件。
我们给identity添加了类型变量T。 T帮助我们捕获用户传入的类型(比如:number),
之后我们就可以使用这个类型。 之后我们再次使用了 T当做返回值类型。现在我们可以知道参数类型与返回值类型是相同的了。
function identify<T>(arg: T): T {
return arg
}
- 泛型类
class GenericNumber<T> {
zeroValue: T;
add: (x: T, y: T) => T;
}
let genericNumber = new GenericNumber<number>();
genericNumber.zeroValue = 0
genericNumber.add = function (x, y) {
return x + y
}
console.log(genericNumber.add(1, 3))
- 泛型函数
- 泛型方法
- 泛型接口
TypeScript 基本数据类型
- enum 枚举
- tuple 元组
- never
- void
- boolean
- number
- string
- null undefined
- typeof null === object
- array
- any
TS 接口 有什么特性
TypeScript 原则之一是对值所具有的结构进行类型检查。 接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。
interface interface_name {
// 字段声明
// 方法声明
}
接口只是声明方法和字段
特性
- 可选属性 ?
- 只读属性
interface Point {
readonly x: number
}
- 类类型
- 继承接口:一个接口可以继承多个接口
高级类型:
- 交叉类型 &
interface interface1 {
a: string
}
interface interface2 {
b: string
}
const mergeType: interface1 & interface2 = {
a: '',
b: ''
}
- 联合类型 |
function padLeft(value: string, padding: string | number) {
// ...
}
ts 断言
- 尖括号类型断言:
<类型>变量名 - as 操作符
变量名 as 类型- 值 as 类型
JSX
JSX是一种嵌入式的类似XML的语法。 它可以被转换成合法的JavaScript, 尽管转换的语义是依据不同的实现而定的。 JSX因React框架而流行,但也存在其它的实现。 TypeScript支持内嵌,类型检查以及将JSX直接编译为JavaScript。
基本用法
- 给文件一个
.tsx扩展名 - 启用
.jsx选项
as 操作符
因为TypeScript也使用尖括号来表示类型断言,在结合JSX的语法后将带来解析上的困难。
因此,TypeScript在.tsx文件里禁用了使用尖括号的类型断言。在 .tsx文件里使用另一个类型断言操作符:as
as 操作符与尖括号类型断言行为是等价的
declare: 声明
- 在 ts 中使用第三方库,需要声明,否则报错
- jQuery wx
- 声明文件:.d.ts
https://ts.xcatliu.com/basics/declaration-files.html
TypeScript 中的 Type 和 Interface 有什么区别
- 发展
- interface 用来描述数据结构,type 用来描述 数据类型
- 一开始先有 interface,后来引入了 type。type 比 interface 灵活多变,一般不能用 interface 实现的,就用 type 实现
- 不同点
- interface 声明可以合并,type 不可以
- type 可以用声明属性,可以用 typeof xxx 赋值声明。 type 可以声明基本类型别名,联合类型,元组等类型
- 相同点
- 可以继承
- 都可以描述一个函数类型
装饰器
ES5 和 ES6 继承有什么区别
写法不同,ES5 继承麻烦不直观,ES6 比较直观
- ES5 继承是通过原型链来实现的
- ES6 为了直观模拟 class 来继承的(通过 class extends + super),本质上也是 prototype 继承的语法糖。
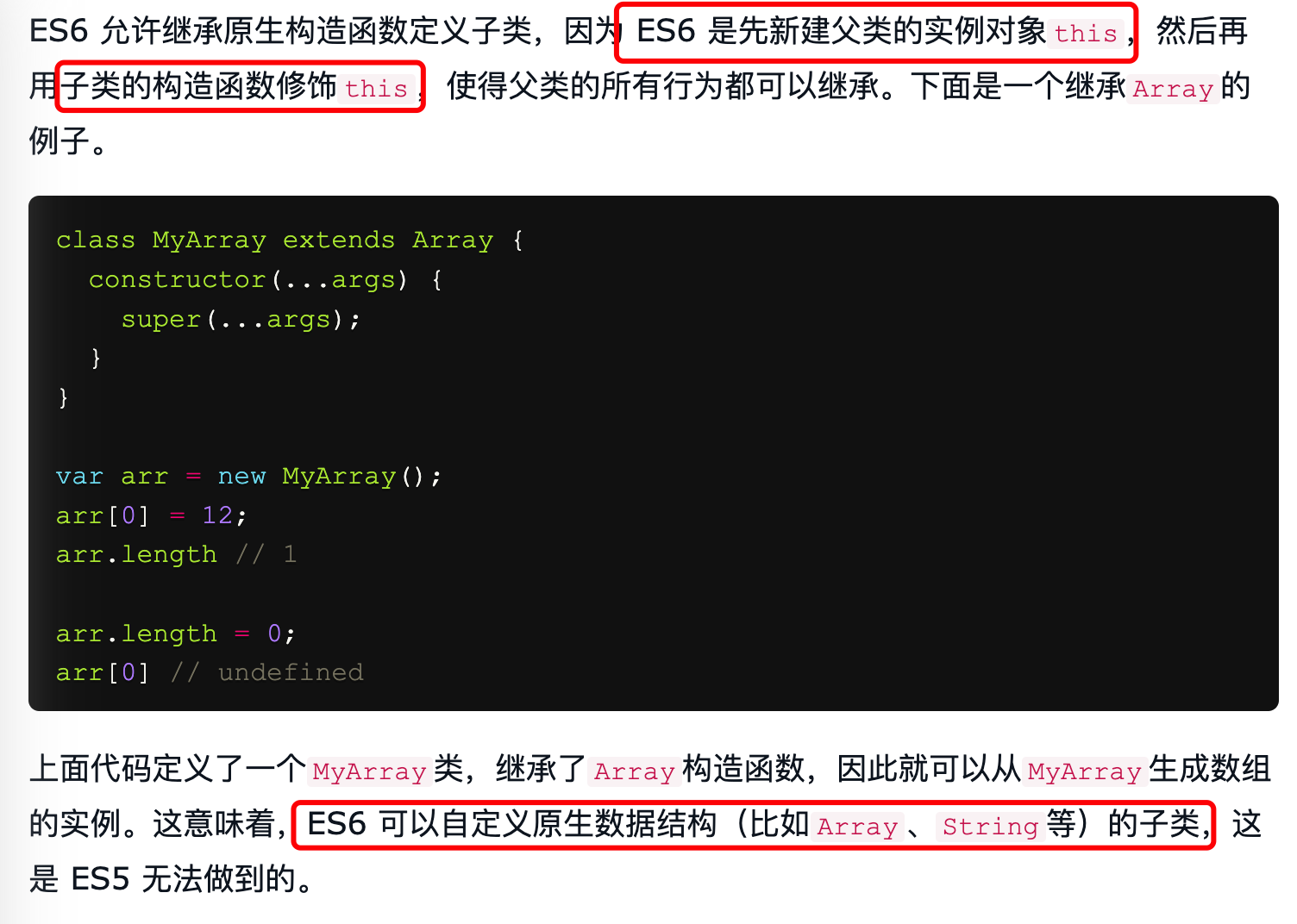
ES5 不可以继承原生构造函数(
原生构造函数有:RegExp Boolean Array Number String Object Date Function Error) ,ES6 可以。原因是两者实现方式不同(核心:第一步建立子类还是父类实例的问题)- ES5 先实例化建立子类对象的
this,再将父类属性添加到子类- 原因:ES5 继承中,子类无法获取原生构造函数的内部属性。eg: Array.apply(this) 忽略了传入的 this
- ES6 是先新建父类的实例对象
this,然后再用子类的构造函数修改this指向父类的实例ES6的继承机制完全不同,实质上是先创造父类的实例对象this, 并将父类的属性和方法放到this上(前提是通过super函数调用), 然后再用子类的构造函数修改this。
- ES5 先实例化建立子类对象的
原生构造函数无法通过 ES5 方式继承。比如,不能自己定义一个 Array 的子类

参考:
如何将两个 TS 合并到一个 JS 中
tsc --outFile common.js ts1.ts ts2.ts

cookies,localStorage,sessionStorage,indexedDB区别
| 特性 | cookies | localStorage | sessionStorage | indexedDB |
|---|---|---|---|---|
| 大小 | 4k | PC 5M,移动端 2.5M | PC 5M,移动端 2.5M | 一般没有大小限制 |
| 与服务器通信 | 每次HTTP请求,都会携带在Header中,对于请求性能有影响 | 不参与 | 不参与 | 不参与 |
| 易用性 | 原生操作比较麻烦,字符串拆解 | 较为易用,键值对总是以字符串的形式存储: setItem() getItem() clear() removeItem() | 较为易用,键值对总是以字符串的形式存储: setItem() getItem | 比较繁琐,支持事务,操作比较麻烦 |
| 生命周期 | 服务器设置时效性 | 除非手动或js删除,否则持久化存储,一直有效 | 关闭浏览器或者页面失效 | 永久 |
| 作用域 | 所有同源窗口共享 | 所有同源窗口共享 | 不能在不同的浏览器窗口共享 | 所有同源窗口共享 |
| 同源策略 | 同源 | 同源 | 同源 | 同源 |
Service Worker
- Service Worker 是运行在浏览器背后的独立线程,不会造成阻塞,一般可以用来实现缓存功能
- 使用 Service Worker 的话,传输协议必须为
HTTPS - 设计为完全异步,同步 API (XHR 或 localStorage)不能在 service worker 中使用
- 实现步骤:
- 注册 ServiceWorkerContainer.register()
- 安装:当 oninstall 事件的处理程序执行完毕后,可以认为 service worker 安装完成了。
- 激活:当 service worker 安装完成后,会接收到一个激活事件(activate event)。 onactivate 主要用途是清理先前版本的 service worker 脚本中使用的资源。
注意:页面初次加载注册成功后,当前页面的 Service Worker 是不能生效的,
因为 register() 成功后的打开的页面才可以让 Service Worker 控制页面,
页面需要重新加载才可以让 Service Worker 生效
实际开发
- uniq 曾经遇到第二次刷新才会更新到的问题.


Cookie Session Token 如何选择
Cookie Session Token 存在的原因: HTTP 无状态,不同请求无法知道是否有关
Cookie: 保存到客户端,有状态,4k 大小限制
- Cookie 有三个目的
- 会话管理: 登录、购物车、游戏得分或者浏览器应该记录的内容
- 个性化:用户偏好、主题或者其他设置
- 追踪:记录和分析用户行为
> 广告跟踪。你上网的时候肯定看过很多的广告图片,
这些图片背后都是广告商网站(例如 Google),它会“偷偷地”给你贴上 Cookie 小纸条,
这样你上其他的网站,别的广告就能用 Cookie 读出你的身份,然后做行为分析,再推给你广告。- 就好比,淘宝在新浪微博和百度搜索中都租了广告位,然后在新浪微博记录个人的信息,然后, 当你去到百度搜索页面的时候,会利用在新浪微博收集的个人信息,显示精准广告。
- 属性:HttpOnly(禁止 document.cookie 使用)、SameSite可以防范跨站请求伪造(XSRF)
- 风险:浏览器和用户可能会禁用Cookie
- 替代方案: URL 参数
- Cookie 有三个目的
Session: 通过 sessionID 保存到服务器端内存中,对分布式、跨系统不友好
Token: 服务端通过算法和一些信息生成的字符串,给客户端进行请求的令牌
- 优点
- 无状态:tokens 里存储用户验证信息,不需要存储 session 信息
- 可扩展:提供可选权限给第三方应用程序,如 github token
- 安全性(时效性): 有时效性,或者通过token revocation 使之失效
- 多平台跨域:跨域
- 优点
选择:
- cookie/session:系统足够小,用户少,简单、易维护
- token: 系统同时登录用户多,集群服务器多,PC移动平板多端同步,有单点登录需求
扩展:JWT (Json Web Token)
参考:
https://blog.mimvp.com/article/39467.html
https://www.cnblogs.com/cxuanBlog/p/12635842.html
https://time.geekbang.org/column/article/106034
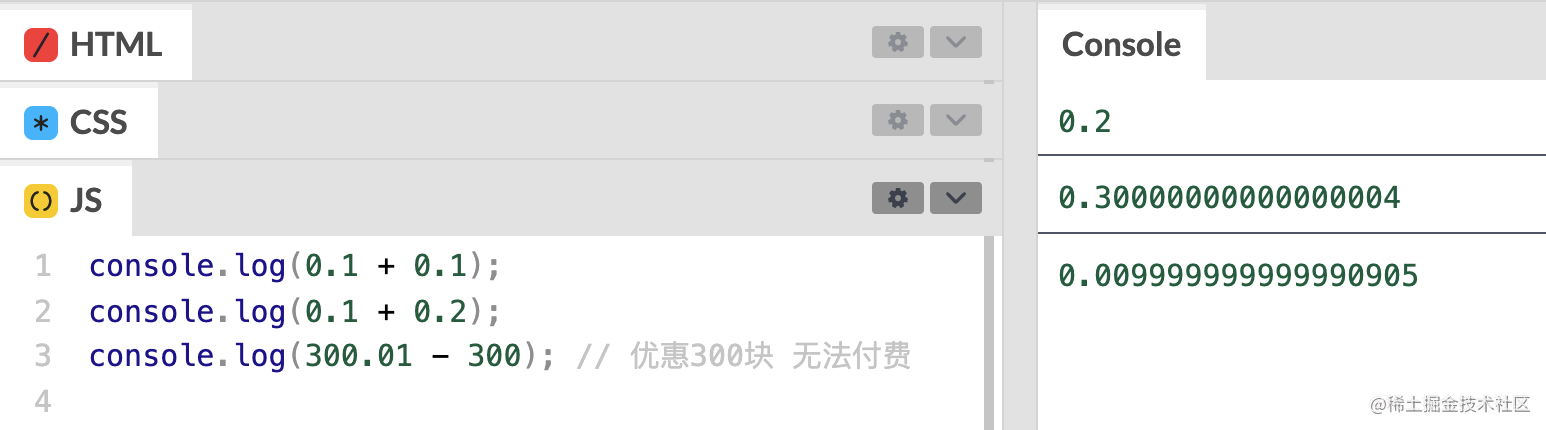
0.1 + 0.2 等于 0.3吗?为什么?如果不等于如何解决?
不等于 0.3。 0.1 和 0.2 这两个实数无法用二进制精确表示。在计算的过程中,会发生精度丢失。
为什么 0.1 + 0.2 != 0.3 呢?首先,0.1 和 0.2 这两个实数无法用二进制精确表示。 在二进制的世界里,只有包含因子 5 的十进制数才有可能精确表示, 而 0.1 和 0.2 转换为二进制后是
无限循环小数,在计算机中存储的值只能是真实值的近似表示, 这里是第一次精度丢失;其次,计算机浮点数采用了 IEEE 754 标准格式,IEEE 754 严格规定了尾数域和指数域可表示的大小,位数有限,意味着可表示的信息量是有限的,换句话说就会存在三种误差:上溢、下溢和舍入误差。 而 0.1 + 0.2 的结果的尾数域部分刚好超过了尾数域位数,超过位数的部分舍去,存在舍入误差, 这里是第二次精度丢失。
- 0.1 和 0.2 转成双精度二进制浮点数时,由于
二进制浮点数的小数位只能存储52位, 导致小数点后第53位的数要进行为1则进1为0则舍去的操作,从而造成一次精度丢失。 - 0.1和0.2转成二进制浮点数后,二进制浮点数相加,小数位相加导致小数位多出了一位,
又要让第53位的数进行
为1则进1为0则舍去的操作,又造成一次精度丢失
单精度(32bit)
8位指数,23位尾数,再加上隐藏的整数1,总共有24位二进制精度
双精度浮点数 64bit
双精度浮点数有11位指数,52位尾数,再加上隐藏的整数1,总共有53位二进制精度

引起BUG:
统计页面显示错误,比如300.01元的产品,优惠了300元,剩下的不是0.01,无法付费
解决办法:
- 使用现有的运算库:bignumber.js Math.js
- 先把数添加10倍,做运算后,再除以10
拓展:
0.1 + 0.1 = 0.2 吗?为什么?
参考资料
列举 ES6、ES7、ES8、ES9、ES10、ES11+ 新特性
列举 ES6、ES7、ES8、ES9、ES10、ES11+ 新特性
ES6 中的 proxy 和 reflect 作用
通过拦截修改默认操作,相当于改写编程语言
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming),即对编程语言进行编程。
Proxy 可以理解成,在目标对象之前架设一层拦截,外界对该对象的访问, 都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。 Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
实例:
- 使用 Proxy 实现观察者模式
const queueObservers = new Set();
// 观察到变化自动执行的函数列表
const observe = (fn) => queueObservers.add(fn); // 1. 将需要触发的函数添加到列表中(Set)
// 观察目标
const observable = (obj) => new Proxy(obj, { set });// 2. 通过 Proxy 对观察目标和观察行为封装绑定
function set(target, key, value, receiver) {
let result = Reflect.set(target, key, value, receiver);
// 3. 拦截 set ,执行列表中的函数
queueObservers.forEach((observe) => observe());
return result;
}
// 调用
const person = observable({
name: "张三",
age: 20
});
function print() {
console.log(`${person.name}, ${person.age}`);
}
observe(print);
person.name = "李四";// 李四,20
person.age = 21;// 李四,21
- 使用 Proxy 实现 代理模式
案例
Vue3 利用 Proxy 实现响应式,深度监听性能优化
Vue2 利用 Object.defineProperty()
Reflect
Object 一些属于语言内部的方法,放到 Reflect 对象中
修改某些Object方法的返回结果,让其变得更合理。比如, Object.defineProperty(obj, name, desc)在无法定义属性时,会抛出一个错误, 而Reflect.defineProperty(obj, name, desc)则会返回false。
让 Object 操作都变成函数行为
// 老写法
'assign' in Object // true
// 新写法
Reflect.has(Object, 'assign') // trueProxy 对象的方法与 Reflect 对象的方法一一对应,Proxy对象可以调用对应的 Reflect 方法完成默认行为, 作为修改行为的基础
反转字符串
// 解法一: 将字符串转为数组,利用Array.prototype.reverse反转数组,再合并数组为字符串
function reverseString(str) {
return str.split('').reverse().join('')
}
reverseString("hello");
// 解法二:新键一个字符串,逆序循环读取字符串,并赋值给新字符串
function reverseString(str) {
var reversedStr = "",
for (i = str.length - 1; i >= 0; i--) {
reversedStr += str[i];
}
return reversedStr;
}
理解Function.prototype.apply.call(fn,thisArg,args),为何要这样用
学习阮一峰reflect中的一个疑惑?
对老写法的不解
// 老写法
Function.prototype.apply.call(Math.floor, undefined, [1.75]) // 1
// 新写法
Reflect.apply(Math.floor, undefined, [1.75]) // 1
前置知识
fn.call(thisArg, arg1, arg2, ...)
// 等价于
fn.apply(thisArg, [arg1, arg2, ...])
// 等价于
thisArg.fn(arg1, arg2, ...)
将 Function.prototype.apply 看做是一个整体
Function.prototype.apply.call(fn, thisArg, args)
// 等价于
// fn.(Function.prototype.apply)(thisArg, args)
fn.apply(thisArg, args)
那么,之前的问题也就可以等价于
Math.floor.apply(undefined, [1.75])
结论
Function.prototype.apply.call(fn, thisArg, args1, args2, ...) 等价于 fn.apply(thisArg, args)
问题来了,为什么不直接使用 fn.apply(thisArg, [...args]),而要这么麻烦的写法呢?
- 兼容 ie 等其他浏览器
https://github.com/facebook/react/issues/13610
参考资料:
理解Function.prototype.apply.call(fn, this Arg, args)
数组去重有几种方法
能写出多少种方法可以体现知识面广度和深度
能想到的知识
- 数据结构与算法的逻辑思维能力
- Set
- Map: has() set()
- Array.indexOf()
- Array.from()
- Array.prototype.some()
- Array.prototype.sort()
- [-9, -8, -7, 9, 8, 7].sort() ??

- [-9, -8, -7, 9, 8, 7].sort() ??
- Array.prototype.filter()
- Array.prototype.splice()
- Array.prototype.includes()
- Object.prototype.hasOwnProperty()
- Array.prototype.reduce()
- 递归去重
参考资料:
Array.from
Array.from({length: 3}, (val, index) => {
console.log('val: ', val)// undefined
return index
})// 生成一个数组 [0, 1, 2]
Array.from 用法
- Array.from(arrayLike, ?mapFn, ?thisArg)
- Array.from(iterable, ?mapFn, ?thisArg)
上述代码中,{length: 3} 对象属于一个有length的对象,所以被认为是一个类似数组的对象(arrayLike)
类似数组(array-like)的对象是指具有类似数组结构的对象,即拥有 length 属性和以数字为键的属性。常见的类似数组的对象包括类似于数组的 DOM 集合(例如 document.querySelectorAll() 返回的结果)和类似于数组的函数参数对象(例如 arguments 对象)。
一个列表(大小不一),拖拽排序,有几种方式
白屏时间过久,有几种可能
https://www.infoq.cn/article/g_yqbu1txmmpeelof8wt
https://www.toptal.com/developers/css/sprite-generator
父子容器,水平垂直居中
- flex 流式布局
#parent {
display: flex;
justify-content: center;
align-items: center;/*复数*/
}
#child {
width: 100px;
height: 100px;
}
- position + translate
#parent {
position: relative; /*形成 Block Formatting Context*/
}
#child {
position: absoltue;
/* 左上角移动到parent区域的中心位置 */
top: 50%;
left: 50%;
/* 以自身宽高的一半为偏移量,向左上角移动 */
transform: translate(-50%, -50%);
}
react class 和 function 组件函数区别, 优缺点
正则表达式
- * 代表
前面的元素出现0、1 或 多次(* 匹配所有次数) - ? 代表
前面的元素出现0或1次(问号,有或无) - + 代表前面的元素
至少出现一次 - . 匹配除换行符(\n、\r)之外的任何单个字符,相等于
[^\n\r]
js 数组遍历方式有哪些
- for...in 迭代对象的可枚举属性,包括原型链上的属性
- forEach 只用于遍历数组
- for...of 迭代可迭代的对象:Array、Map、Set、Object、String
Array.prototype.forEach
- 不修改原数组
- return 中断此次循环,不能终止循环,除了抛出异常
- 不返回
Array.prototype.map
- 不修改原数组
- 返回 map 中修改后的元素,组成的数组
Array.prototype.find
Array.prototype.findIndex
for
for...in
for...of
Array.prototype.filter
Array.prototype.every
Array.prototype.some
// 1. forEach
let arr = ["aa", "bb", "cc", "dd"];
let temp = [];
let res = arr.forEach((item) => {
if (item === "aa") {
return;
}
temp.push(item);
});
console.log("forEach 只是做遍历,不会修改原数组:", arr);
console.log(
"forEach 循环体中 return 只是跳出此时的循环,除了抛出异常终止循环,没有其他办法终止循环:",
temp
);
console.log("forEach 不返回:", res);
// 2. map
res = arr.map((item) => item + "l");
console.log("map 不修改原数组: ", arr);
console.log("map 返回值组成新数组,: ", res);
let objArr = [
{ name: "Tom", score: 80 },
{ name: "Tony", score: 81 },
{ name: "Sam", score: 90 },
{ name: "Lili", score: 70 }
];
// 3. filter
res = objArr.filter((item) => item.score > 80);
console.log("filter 不修改原数组 objArr:", objArr);
console.log("filter 返回符合条件的元素,组成一个新数组:", res);
// 4. every 数组中每一个元素是否都符合条件
//let bool = objArr.every((item) => item.score > 80);// false
let bool = objArr.every((item) => item.score > 60); // 都及格 true
console.log("every 不修改原数组 objArr:", objArr);
console.log("every 数组中每一个元素是否都符合条件:", bool);
// 5. some 数组中存在一个元素符合条件
bool = objArr.some((item) => item.score >= 90);
console.log("some 不修改原数组 objArr:", objArr);
console.log("some 数组中存在某个元素,符合条件:", bool); // true
// 6. find 数组中寻找符合条件的一个元素
let resItem = objArr.find((item) => item.score > 80);
console.log(
"find 数组中寻找符合条件的第一个元素,返回符合条件的元素,不是数组:",
resItem // { name: "Tony", score: 81 }
);
// 7. findIndex
let resIndex = objArr.findIndex((item) => item.score > 80);
console.log("findIndex 不修改原数组 objArr:", objArr);
console.log(
"findIndex 数组中寻找符合条件的第一个元素的index,并放回index:",
resIndex
); // 1
// 8. for...in
for (let index in objArr) {
console.log("for...in:", index);
console.log("for...in:", objArr[index]);
}
// 9. for...of 同步遍历,遍历完一层,阻塞
for (let item of objArr) {
console.log("for...of:", item);
}
// 10. for
for (let i = 0; i < objArr.length; i++) {
console.log("objArr[i]:", objArr[i]);
}
- for...in forEach for是常规的异步遍历,所有循环同时发生
- for...of 用于同步遍历
- 注意区分:网络的同步阻塞,异步HTTP请求
- for...in forEach for同步遍历指的是,多个循环同时执行
- for...of 同步(阻塞)遍历,迭代方式是同步的, 即一次只迭代一个元素,直到迭代完所有元素为止。 如果循环的对象是异步的(如 Promise), 那么需要使用 await 来等待异步操作完成后才能进行下一次循环。
在 forEach 循环、for-in 循环和普通的 for 循环都是同步循环,,异步函数 muti 是被调用了三次,但是由于异步函数的特性, 代码会一下子执行完毕,因此打印出结果时也是一下子打印出来的,没有等待异步函数的返回结果。
在 for-of 循环中,由于使用了 await 关键字,异步函数 muti 的执行被阻塞了,直到该异步函数执行完毕并返回结果后才会继续执行下一个循环。因此,这个循环会等待每个异步函数的返回结果,再打印出该结果。因为每个异步函数执行的时间是 1 秒钟,所以每个结果之间会有 1 秒钟的间隔。这种方式可以确保按照正确的顺序打印出每个异步函数的结果,而不会出现错乱的情况。
function muti(num) {
return new Promise((resolve) => {
setTimeout(() => {
resolve(num * num);
}, 1000);
});
}
const nums = [1, 2, 3];
// nums.forEach(async (i) => {
// const res = await muti(i);
// console.log(res);// 一下子打印
// });
!(async function () {
for (let j of nums) {
const res = await muti(j);
console.log(res); // 异步打印 阻塞打印,等待一秒后打印1,1s后打印4,1s后打印9
// 有结果后再执行下一个
}
})();
// for...in 迭代的是属性 key, 返回的是所有继承链的属性,有必要时会用到 hasOwnProperty
const arr = ['a', 'b', 'c']// 也可以是对象,object
for(let i in arr) {
console.log(i) // 0 1 2
}
// for...of 迭代的是 value
const arr = ['a', 'b', 'c']
for(let i of arr) {
console.log(i) // a b c
}
Day353:React Hooks 解决了什么问题?其原理是什么(以 useEffect 为例)?useMemo 和 useCallback 差别?
React Hooks 方便了函数式编程,原理是语法糖。
函数里没有生命周期,通过 React Hooks 可以模拟生命周期
useMemo和useCallback差别:
- 相同点:
- 都是作为性能优化。
- 类似 shouldComponentUpdate
- 避免父组件渲染时,子组件重复渲染
- 不同点:
- useCallback 传入一个函数和数组,返回一个记忆函数,如果数组中的state修改了,才会被调用
- useMemo 避免进行高开销的计算,返回一个值
- 场景
- useCallback: 父组件更新时,通过props传递给子组件的函数也会重新创建,然后这个时候使用 useCallBack 就可以缓存函数不使它重新创建
- useMemo: 组件更新时,一些计算量很大的值也有可能被重新计算,这个时候就可以使用 useMemo 直接使用上一次缓存的值
useRef 和 creatRef 的区别
- createRef 每次渲染都会返回一个新的引用,而 useRef 每次都会返回相同的引用。
useEffect 与 useLayoutEffect 的区别
主要是:调用时机不同
useEffect【是异步宏任务】:赋值给 useEffect 的函数会在组件
渲染到屏幕之后执行useLayoutEffect【是异步微任务】: 顾名思义,layout and paint, 也就是在 layout 后和 paint 之前触发 useLayoutEffect 与 componentDidMount、componentDidUpdate 生命周期钩子是【异步微任务】。 在浏览器执行
绘制之前,useLayoutEffect 内部的更新计划将被同步刷新。 在所有的 DOM 变更之后同步调用 effect- 把操作 dom 的相关操作放到 useLayouteEffect 中去,避免导致闪烁。
- useLayoutEffect 是不会在服务端执行的,所以 SSR 不可以使用
useLayoutEffect
根据宏任务、微任务、尝试 DOM 渲染 顺序问题
1. call stack 一行一行执行代码
2. 执行当前微任务
3. 尝试 DOM 渲染
4. 触发 event Loop,执行一个宏任务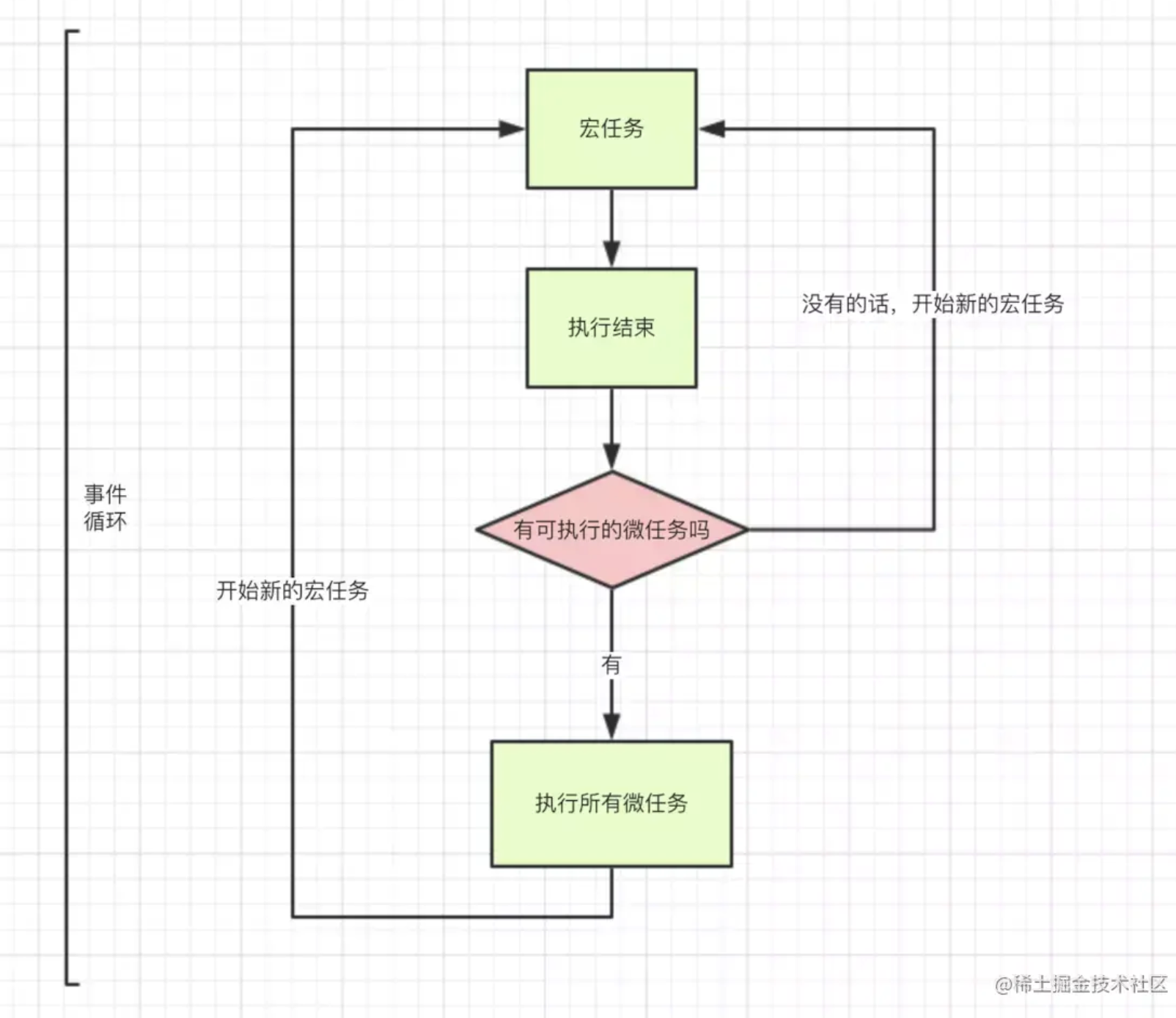
堆和栈的区别
- 堆:存储对象,内存分配不连续,存储的是对象的地址
- 对象的地址指向堆内存,堆内存中存储的是对象的属性
- 栈:存储基本类型,内存分配连续,存储的是值
调用栈
优化以下代码,防止栈溢出 Maximum call stack
function foo(n) {
if (n === 0) {
return 0;
}
foo(n - 1)
}
foo(50000)
// 优化一:宏任务,不入栈
function runStack (n) {
if (n === 0) return 100;
return setTimeout(function() {
runStack( n- 2)
}, 0);
}
runStack(50000)
// 优化二:蹦跳函数
function runStackTwo(n) {
if (n === 0) return 100;
return runStackTwo.bind(null, n - 2);// bind 会返回一个新的函数
}
// 入栈一个函数,执行完再入栈一个函数,因为bind返回新函数,运动员一上(出栈)一下(入栈)
function trampoline(fn) {
while (fn && fn instanceof Function) {
fn = fn();// 执行完后,fn 会被赋值为新的函数
}
return fn;
}
trampoline(runStackTwo(50000))
箭头函数和普通函数有什么区别
- this 指向问题
箭头函数
- 由于 箭头函数没有自己的this指针,通过 call() 或 apply() 方法调用一个函数时, 只能传递参数(不能绑定this---译者注),他们的第一个参数会被忽略。
interface Padding {
top: number,
right: number,
bottom: number,
left: nubmer
}
padding(1)
padding(1, 2)
padding(1, 2, 3)
padding(1, 2, 3, 4)
/* 上边 | 左边右边 | 下边 */
// padding: 1em 2em 2em;
console.log(padding(1, 2, 3), "top = 1 bottom = 3 right = left = 2"); // padding 传三个值时候
console.log(padding(1, 2, 3, 4));
function padding(v1, v2?: number, v3?: number, v4?: number) {
let p: Padding = {
top: v1,
right: v2 ?? v1,
bottom: v3 ?? v1,
left: v4 ?? v2 ?? v1
};
return p;
}
let me try 知识点
- ?? 空值合并运算符
- 当左侧操作数为 null 或 undefined 时,返回右侧操作数
单页面应用
优缺点、实现原理、对比多页面应用、什么时候选择单页面应用
| 单页面应用 | 多页面应用 | |
|---|---|---|
| 组成 | ||
| SEO | 不利于SEO(可借助 SSR 优化 SEO) | 对 SEO 友好 |
| url |
- 只加载一次,
强缓存,客户端不与服务器交互。图片更新后,如何客户端取到最新的图片
(不更新页面的前提下,只更新后台静态资源)
添加时间戳作为url的参数,每次请求,url都是不同的,所以不会走强缓存的流程。

与添加 MD5 的区别
- 唯一标识,当静态资源文件更新了,MD5 才会变,会用另一个静态资源文件,而不是用以前的
- 这个是更新页面的应用
浏览器打开一个 tab 是属于进程还是线程
进程。但是打开一个 tab ,会启动不止一个进程。
- 浏览器进程
- 网络进程
- 渲染进程
- GPU 进程
线程与进程
- 线程运行在进程里
- 一个进程可以有多个线程
- 多个线程可以同时并行运行
- 线程之间共享进程中的数据
初始化二维数组
初始化二维数组误区 (放入引用类型),导致 a[0] 引用了 a[1] 引用了 a[2]

因为:如果value值为一个引用数据类型,则 fill 之后,数组里面的值指向的是同一个地址。
正确初始化
let n = 3, matrix = new Array(n).fill(0).map(() => new Array(n).fill(0))
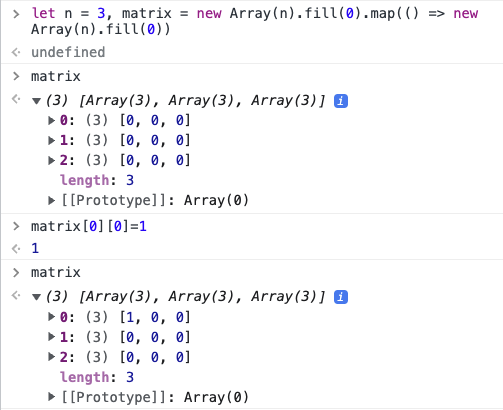
第一次 new Array(n).fill(0) 是为了 map 迭代,如果不 fill,则无法迭代
new Array(3).map(() => 1)// [emptyX3]
new Array(3).fill(0).map(() => 1)// [1,1,1]

如何编写可扩展性代码
- 编写符合设计原则代码,使用设计模式
- 多用组合少用继承
- 组件化开发
- 开闭原则:扩展开放,修改关闭
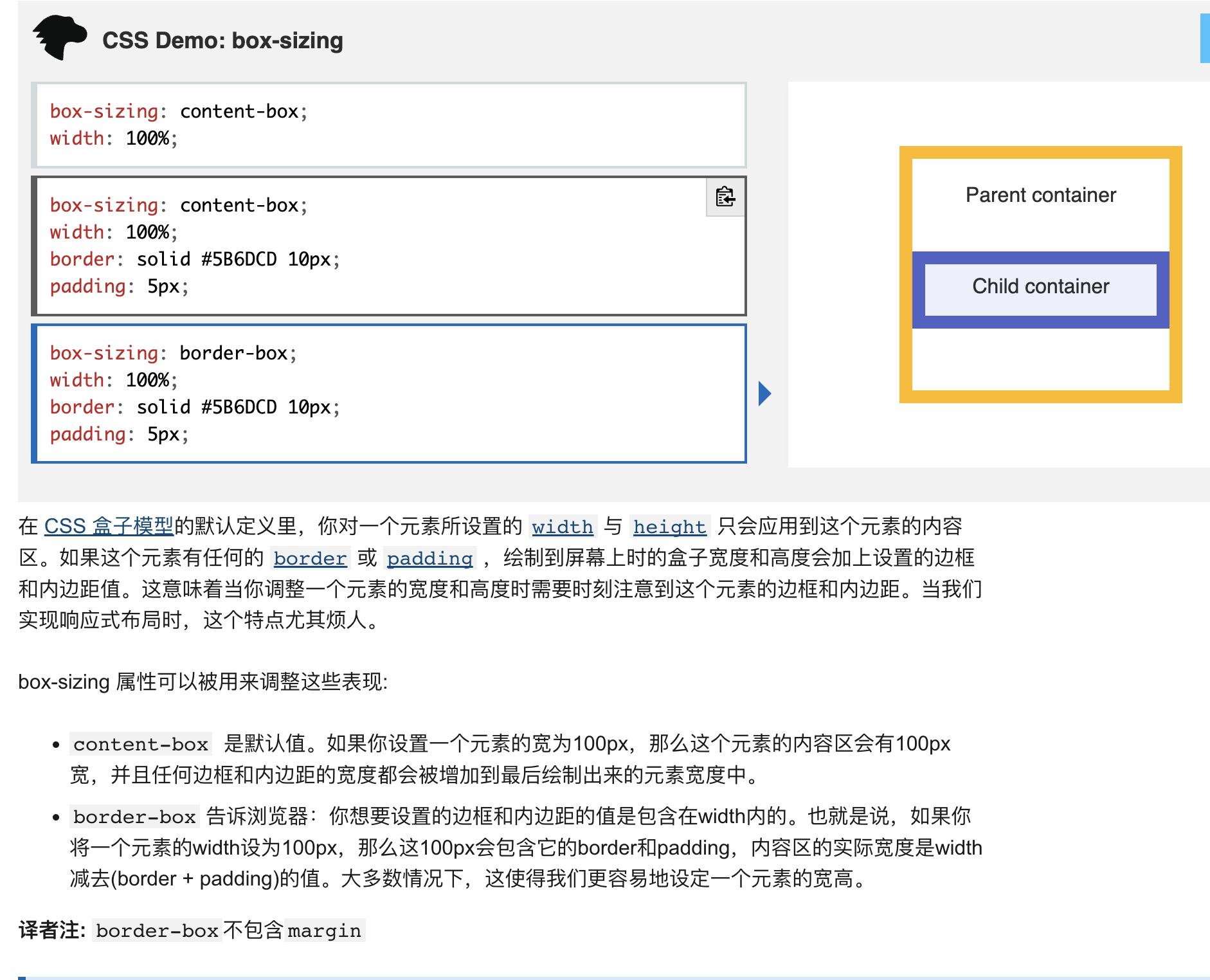
box-sizing
- context-box: 内容盒子。就是宽度不包含 border 和 padding
- border-box: 边框盒子。就是宽度包含 border 和 padding。不包含margin
路由实现原理
由于现在是单页面应用,一个页面里包含很多个组件,跳转切换页面,其实就是组件间的切换, 所以需要用路由模拟。
react-router

hash 模式原理
当URL的片段标识符更改时,将触发hashchange事件 (跟在#符号后面的URL部分,包括#符号)
window.location.hash可获取和设置 hash 值
- 监听路由变化
document.addEventListener('hashchange', function (e) => {})
window.addEventListener('hashchange', function() {
console.log('The hash has changed!')
}, false);
history 模式原理
使用 Web API history 实现
路由跳转
history.pushState(state, title[, url])方法向当前浏览器会话的历史堆栈中添加一个状态(state)。history.go()负值表示向后移动,正值表示向前移动window.history.back()相当于window.history.go(-1)window.history.forward()相当于window.history.go(1)history.replaceState(stateObj, title[, url])
监听路由变化 document.addEventListener('popstate', function(e) => {})
- 当用户点击浏览器的回退按钮(或者在
Javascript代码中调用history.back()或者history.forward()方法)时,会触发popstate事件 history.pushState(),history.go(),history.forword()不会触发popstate
理解 History 封装库
在 hash 模式下,history.push 底层是调用了 window.location.href 来改变路由。
history.replace底层是调用 window.location.replace 来实现的
/* 对应 push 方法 */
const pushHashPath = (path) =>
window.location.hash = path
/* 对应replace方法 */
const replaceHashPath = (path) => {
const hashIndex = window.location.href.indexOf('#')
window.location.replace(
window.location.href.slice(0, hashIndex >= 0 ? hashIndex : 0) + '#' + path
)
}
TODO: 画图
核心:
- 路由变化监听的事件
- history:
popstate - hash:
hashchange
- history:
- 路由变动底层两种模式分别调用了什么 API
- history:
window.history.pushStatewindow.history.replaceState - hash:
window.location.hrefwindow.location.replace
- history:
react-router history 属性

参考:
纯函数
- 相同的输入,需产出相同的输出
- 不能有可观察的函数副作用。例如:
- http 请求
- 修改 DOM
- console.log()
- 修改外部数据
- 纯函数必须是确定性的,以下方法不确定:调用 Date.now() 或者 Math.random()
纯函数的好处
- 可预测性,消除外部因数和环境变化将使函数更加健全和可预测
- 可维护性:可预测的函数更容易推理。减少状态假设和开发人员的认知负荷
- 可测试性: 函数的自我约束和独立性将提升可测试性
在应用程序性能方面
- 可缓存:函数的确定性使我们能够通过输入预测输出,基于输入就可以缓存
纯函数的应用
- 数组基本方法:map, filter, forEach, reduce
- redux 中的 reducer
Reducer 只是一些纯函数,它接收先前的 state 和 action,并返回新的 state。 -- Redux 中文文档
- Lodash
纯函数是什么?怎么合理运用纯函数? 函数式编程(三):纯函数的重要性
严格模式和非严格模式
使用方式
- 严格模式:
'use strict' - 非严格模式:默认模式
区别
在 JavaScript 中,严格模式和非严格模式是两种不同的代码执行模式。严格模式是通过在脚本或函数顶部添加 'use strict'; 来启用的。
严格模式相对于非严格模式有以下区别: 好的,以下是例子:
- 变量必须先声明再使用。如果没有先声明变量就使用它,将会抛出错误。
'use strict';
x = 10; // ReferenceError: x is not defined
在严格模式下,如果使用未声明的变量,会抛出一个ReferenceError异常。
- 禁止删除变量、函数或函数参数。在非严格模式下,可以使用 delete 操作符删除一个属性甚至整个对象。
'use strict';
var obj = {x: 10};
delete obj.x; // ok
delete obj; // TypeError: Cannot delete property 'obj' of [object Object]
在严格模式下,不能删除一个没有被声明的变量,也不能删除函数名、函数参数、catch字句中的变量,否则会抛出SyntaxError异常。此外,尝试删除一个不可配置(non-configurable)的属性时,会抛出TypeError异常。
- 在函数调用时,this 的值是 undefined。在非严格模式下,如果 this 值为 null 或 undefined,则会自动替换为全局对象(指 window)。
'use strict';
function foo() {
console.log(this); // undefined
}
foo();
在严格模式下,如果函数不是以方法的形式调用(即不作为对象的属性),那么在函数内部,this的值为undefined。
- 禁止使用 with 关键字。with 关键字被认为是过于危险而被废弃了,因为它可能会导致意外的命名冲突和性能问题。
'use strict';
var obj = {x: 10};
with (obj) {
x = 20;
}
console.log(obj.x); // TypeError: Cannot use 'with' statement in strict mode
在严格模式下,使用with语句将会抛出一个TypeError异常。
对象字面量中定义重复属性会抛出错误。在非严格模式下,重复属性会被忽略。
测试结果显示:严格模式下并没有报错
'use strict';
var obj = {x: 10, x: 20}; // SyntaxError: Duplicate data property in object literal not allowed in strict mode
在严格模式下,如果在对象字面量中定义了两个同名的属性,会抛出一个SyntaxError异常。
- eval 函数创建的变量和函数作用域仅限于 eval 内部。在严格模式下,eval 中创建的变量和函数只能在 eval 内部使用。
'use strict';
eval('var x = 10;');
console.log(x); // ReferenceError: x is not defined
在严格模式下,eval函数执行时创建的变量和函数不会被添加到周围的作用域中,因此无法从eval外部访问它们。
网易 三七
单选题
浏览器读取资源的顺序是(Memory Disk 请求服务器)
- A. Memory Disk 请求服务器
- B. Disk Memory 请求服务器
- C. 请求服务器 Memory Disk
- D. 请求服务器 Disk Memory
- E. Memory 请求服务器 Disk
- F. Disk 请求服务器 Memory
假设下面选择符最终都指定到同一元素上,请选出以下权重最高的一个CSS选择符(2分)
- A. test1[data-index1] // data-index1 为属性选择器, 表示具有 data-index1 属性的元素
- B. #test p;
- C. test11 test10 test9 test& test test6 test5 test4 test3 test2 testi
- D. #test test1
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>CSS选择器测试</title>
<style>
.test11[data-index1] {
color: red;
}
#test p {
color: green;
}
.test1 .test2 .test3 .test4 .test5 .test6 .test7 .test8 .test9 .test10 .test11 {
color: blue;
}
#test .test11 {
color: purple;
}
</style>
</head>
<body>
<div id="test">
<p class="test1" data-index1="1">This is a test</p>
<div>
<ul>
<li>
<div class="test1">
<div class="test2">
<div class="test3">
<div class="test4">
<div class="test5">
<div class="test6">
<div class="test7">
<div class="test8">
<div class="test9">
<div class="test10">
<p class="test11" data-index1="1">这是一个被选择器匹配的元素</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</li>
</ul>
</div>
</div>
</body>
</html>
答案:D
js中以下结果为true的是(2分)
- A. NaN==NaN // NaN 不等于任何值,包括它自己
- B. false==null // typeof null === 'object', typeof false === 'boolean'
- C. 0==undefined //
- D. false=='0'
答案:D
null == undefined // true
false == null // false
知识点:类型转换
自动类型转换为布尔值
- 在条件语句中,JavaScript 会将以下值自动转换为 false:false、null、undefined、空字符串("")、0 和 NaN
- 其他所有值都会被转换为 true。
null 和 undefined
- null 表示一个空对象指针,转为数值时为 0:
null + 1 = 1 - undefined 表示值未定义,转为数值时为 NaN:
undefined + 1 = NaN
- null 表示一个空对象指针,转为数值时为 0:
正则
var a = /123/; var b = /123/; console.log(a == b) console.log(a === b)
解析:正则表达式是对象,对象是引用类型,引用类型比较的是地址,所以结果都为 false
let a = {
name: 'Test',
obj: {
title: 'example'
}
};
let b = Object.assign({}, a);
b.name = "New";
b.obj.title = "New Test";
console.log(a.name);
console.log(a.obj.title);
答案:Test ,New Test。object.assign() 浅拷贝
以下哪些是vue的通信方式,请选择
- A. props/emit
- в. 中间组件bus
- c. vuex
- D. Sparent/Schildren
- E. provider/inject
- F. slot-scope
Sparent/Schildren和slot-scope是Vue.js的一些概念和功能,不是通信方式。
props/emit:父组件通过props向子组件传递数据,子组件通过emit触发事件向父组件传递数据。
中间组件bus:通过一个空的 Vue 实例作为中央事件总线(事件中心),用它来触发事件和监听事件,从而实现组件间的通信。
vuex:是一个专为 Vue.js 应用程序开发的状态管理模式。vuex中集中存储了多个组件所需的共享状态,可通过Action提交Mutation,更改状态。当然,也支持通过Getter获取状态值。
provider/inject:祖先组件通过provider提供数据,后代组件通过inject注入数据。用于祖先组件向后代组件传递数据。
break
以下哪种遍历循环方式能通过break退出(4分)
- for
- forEach
- while
- map
forEach和map都是数组的遍历方法,不能通过break退出。
vue 实例的 data 属性,可以在哪些生命周期中获取到?
- beforeCreate
- created
- beforeMount
- mounted
多选题
×ss 跨站脚本攻击方式
- A. 引入暂时型的JS代码
- B. 修改网页代码
- C. 通过input输入框引1入破坏性代码
- D. 盗取用户cookie
A: 注入 JS 代码 B: 注入 HTMl 或 CSS,例如插入钓鱼页面或者欺骗用户点击恶意链接等。
VDOM
对虛批dom描述正确的是?
- A、直接用JavaScript实现了DOM树
- B、组件的HTML结构并不会直接生成DOM,而是映射生成虚拟的JavaScript DoM结构
- C、React又通过在这个虚拟DOM上实现了—个di算法找出;最小变更,再把这些变更写入实际的DON中
- D、这个虚拟DOM以JS结构的形式存在,计算性能会比较好,而且由于减少了实际口OM操作次数,性能会有较大提 升
ans: BCD
A: 虚拟 DOM 并不是直接用 JavaScript 实现了 DOM 树。
虚拟 DOM 可以理解为一个抽象的 JavaScript 对象树,它是一个虚拟的映射,用来表示真实 DOM 树中的节点和属性。 虚拟 DOM 节点和属性的数据结构和操作方式都和真实 DOM 类似,但是不需要直接操作真实 DOM 树,而是通过在虚拟 DOM 树上进行操作来最终生成真实的 DOM 树。
下列对 Vue2 原理的叙述,哪些是正确的?
- A vue 中的数组变更通知,通过拦截数组操作方法而实现
- B 编译器目标是创建渲染函数,渲染函数执行后将得到 VNode 树
- C 组件内 data 发生变化时会通知其对应 watcher,执行异步更新
- D patching 算法首先进行同层级比较,可能执行的操作是节点的增加、删除和更新
知识点
响应式:
vue2 中的数据响应式是通过 Object.defineProperty() 来实现的,通过数据劫持的方式来监听数据的变化,当数据发生变化时,会通知对应的 watcher,从而执行相应的操作。
vue3 中的数据响应式是通过 Proxy 来实现的,Proxy 是 ES6 中新增的一个 API
// 通过 reactive 包裹一个对象,返回一个响应式的对象
const state = reactive({
count: 0
})
答案:ABCD
以下哪些是规范类型
- A. Reference
- B. List
- C. Property Identifier
- D. Symbol variable
- E. Environment Record
- F. Root
chatgpt:
A. Reference(引用):不是规范类型,它是一个值的内部属性,用于引用其他值。
B. List(列表):不是规范类型,它是一种数据结构,用于存储多个值。
C. Property Identifier(属性标识符):是规范类型,它是指在对象字面量中定义属性时使用的名称。
D. Symbol variable(符号变量):是规范类型,它是ES6中引入的新数据类型,用于创建唯一的值。
E. Environment Record(环境记录):是规范类型,它是ECMAScript的内部数据结构,用于存储变量和函数声明。
F. Root(根):不是规范类型,它是一个术语,用于描述树状结构中的最上层节点。
以下哪种dom元素获取方式获取的是动态集合
• A. getElementByld • B, getElementsByTagName • C. querySelector • D. querySelectorsAll
const el = document.querySelector(".myclass");
答案:B D
简答
1、解释—下let和const为什么不像var能在变量声明赋值前被调用,需要说明对变量提升的理解
let 和 const 是块级作用域,不存在变量提升
在声明后不初始化的时候会产生暂时性死区(TDZ),在 TDZ 中访问变量会报错。
console.log(x); // ReferenceError: x is not defined
let x = 10;
var 存在变量提升,如果在声明前使用,会返回 undefined
console.log(x); // undefined
var x = 10;
2、请简单说明下webpack的工作流程以及简单分析下构建后的JS产物是怎么处理模块导入和依赖关系
- webpack 的工作流程
- 构建后的 JS 产物是怎么处理模块导入和依赖关系
3、谈谈你对浏览器缓存策略的理解,需要说明下缓存存储读取的规则
- 分强制缓存和协商缓存
- 强制缓存:
Cache-Control、Expires - 协商缓存:
Last-Modified、If-Modified-Since、Etag、If-None-Match- 响应时告诉浏览器:Last-Modified(上次修改时间)、Etag(指纹)
- 请求时携带
If-字段,询问是否符合:If-Modified-Since、If-None-Match,如果资源未更新,则返回 304
- 强制缓存:
4、写一段vue模板代码以及其转译后的render代码
编程
1、实现sum函数
// sum(1)(2)(3)() === 6
// sum(1,2,3) === 6
知识点:
- 函数柯里化:
function sum() {
let args = []
let fn = function() {
let fn_args = Array.prototype.slice.call(arguments)
args = args.concat(fn_args)
return fn
}
fn.toString = function() {
return args.reduce((a, b) => a + b)
}
return fn.apply(null, arguments)
// return fn(...arguments)
}
// alert(sum(1)(2)(3))// 6
// alert(sum(1,2,3))// 6
console.log(sum(1)(2)(3).toString())// 6
console.log(sum(1, 2, 3).toString())// 6
console.log(sum(1, 2, 3, 4).toString())// 6
console.log(sum(1).toString())// 6